Replication Vs Partitioning
Replication
Keeping a copy of the same data on several different nodes, potentially in different locations. Replication provides redundancy: if some nodes are unavailable, the data can still be served from the remaining nodes. Replication can also help improve performance.
There are two parts to this definition.
- Keeping the same data on multiple machines
- It’s required to store the copies that are exactly the same as the original data everywhere. The purpose is to use multiple machines to serve users. We would want to handle the increasing volume of reads and writes using more machines, as discussed previously.
- The machines are connected via a network
- If the machines are not connected via a network, then they cannot communicate creations, changes, or updates to the data. Remember that the machines need to have the exact same data stored in them. To keep them always in sync, there has to be network communication.
- Of course, keeping the data same across machines is easy if your data is static and never changes. You can just run multiple machines with a copy of the same data and serve the clients. Network communication between the storage nodes is not required.
In distributed systems, we need data replication to still work even if it partially fails. Also, with replication, we can scale the system when the business grows. Most systems do have data that changes over time. For many systems, network communication between storage nodes is a must to keep the data consistent across all the nodes.
Now, this might sound so simple—to have a couple of nodes and copy data from one to another via a network—but unfortunately replication is a difficult problem to solve in a system that requires it. Networks are unreliable. Machines fail randomly, and storage capacity has its limits. With more data comes more problems.
Partitioning
Partitioning in a database is like breaking down a really big table into smaller pieces. Imagine you have a huge table, and instead of dealing with all of it at once, you split it into smaller parts. This helps speed up certain tasks because when you're looking for something, you only have to search through a smaller chunk of data, making things quicker.
The main reason we do this is to make it easier to manage large tables. It's like organising your stuff into smaller boxes rather than dealing with one giant container. This not only helps with keeping things tidy but also makes it faster when you need to find or add specific information in the table.
This concept is also known as Sharding.
Replication Vs Partitioning
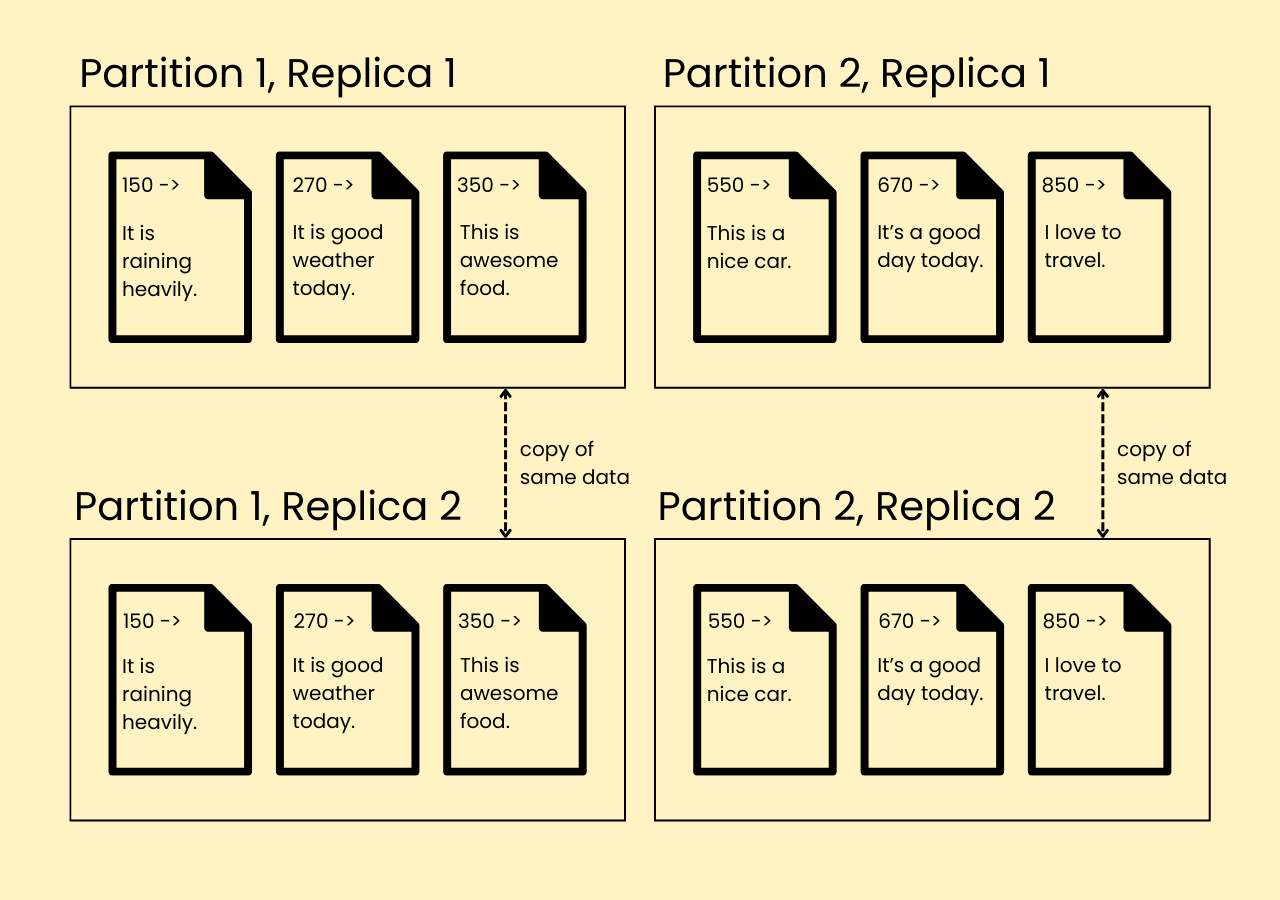
Why do we need Replication?
- To keep data geographically close to your users (and thus reduce latency).
- To allow the system to continue working even if some of its parts have failed (and thus increase availability).
- To scale out the number of machines that can serve read queries (and thus increase read throughput).